A customer sent me an interesting request today asking how to connect Microsoft Access to Snowflake. I connected Excel to Snowflake, but had never tried with Access. I thought that since they’re both Microsoft Office products, it would work pretty much the same. That turned out not to be the case, at least at first.
A bit of research indicated that Access doesn’t ask for credentials; you have to store them in the Data Source Name (DSN). It’s possible to use Visual Basic for Applications (VBA) to ask for credentials each use, but it introduces other issues. On the other side of the connection, Snowflake does not store credentials in the ODBC DSN. You have a standoff situation.
Fortunately there’s an easy and robust solution. CData, a company specializing in data access and connectivity solutions, has a Snowflake ODBC driver. CData has a reputation for high-quality products. Developers often choose to use their ODBC or other connectors instead of the ones database companies provide free. The CData ODBC driver for Snowflake comes with a 30-day free trial and is bi-directional. You can read from and write to Snowflake with it.
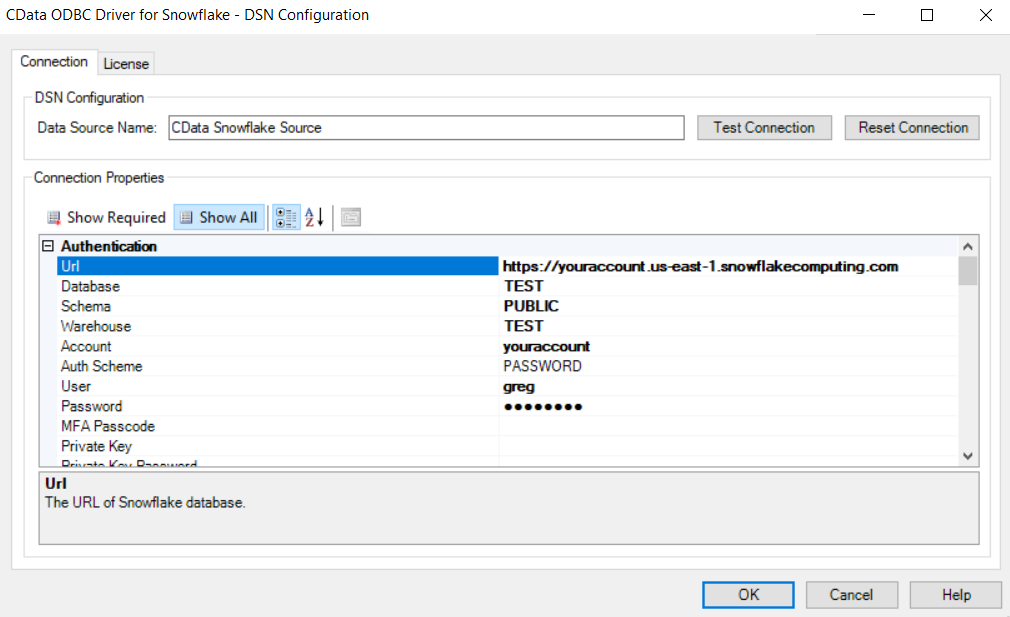
Connecting Access to Snowflake is easy. In the “Url” box, take your Snowflake URL and enter the complete URL up to and including “snowflakecomputing.com” and enter it. In the “Account” box, enter just the first part after https:// not including any indicator of location such as us-east1. For example:
This User Defined Function (UDF) doesn’t require much explanation. Payment card number goes in; payment card type comes out. Since it is designed for speed, it does not validate the check digit. A subsequent post will provide a UDF to validate the check digit using the Luhn algorithm.
/********************************************************************************************************************
Function: PaymentCardType
Description: Decodes the type of payment card from Visa, Mastercard, AMEX, etc.
Parameters: A string indicating the type of payment card, or a blank string if not identified.
*********************************************************************************************************************/
create or replace function PaymentCardType(cardNumber string)
returns string
language javascript
strict
as '
//Remove all spaces and dashes. Simply ignore them.
NUMBER = CARDNUMBER.replace(/ /g, "");
NUMBER = NUMBER.replace(/-/g, "");
// Visa
var re = new RegExp("(4[0-9]{15})");
if (NUMBER.match(re) != null)
return "Visa";
// Mastercard
re = new RegExp("(5[1-5][0-9]{14})");
if (NUMBER.match(re) != null)
return "Mastercard";
// AMEX
re = new RegExp("^3[47]");
if (NUMBER.match(re) != null)
return "AMEX";
// Discover
re = new RegExp("^(6011|622(12[6-9]|1[3-9][0-9]|[2-8][0-9]{2}|9[0-1][0-9]|92[0-5]|64[4-9])|65)");
if (NUMBER.match(re) != null)
return "Discover";
// Diners
re = new RegExp("^36");
if (NUMBER.match(re) != null)
return "Diners";
// Diners - Carte Blanche
re = new RegExp("^30[0-5]");
if (NUMBER.match(re) != null)
return "Diners - Carte Blanche";
// JCB
re = new RegExp("^35(2[89]|[3-8][0-9])");
if (NUMBER.match(re) != null)
return "JCB";
// Visa Electron
re = new RegExp("^(4026|417500|4508|4844|491(3|7))");
if (NUMBER.match(re) != null)
return "Visa Electron";
return "";
';
-- Test the UDF:
select PaymentCardType('4470653497431234');
The term stream has a lot of usages and meanings in information technology. This is one of the reasons the Snowflake stream feature has excited interest, but also raised confusion. Technologists often use the term stream interchangeably with a platform for handling a real-time data feed, such as Kafka. Snowflake streams are something different.
Often distinctions in technology are subtle. Fortunately this isn’t one of those times. Snowflake streams are nothing like Kafka, Spark Streaming or Flume. They capture change data, i.e., CDC and show the changes in a table. Also, Snowflake streams are not always “streaming”. They capture changes to a table whether they’re happening in a stream, micro-batches, or batch processes.
Why use stream tables
There are lots of reasons. One of the most common is keeping a staging table and production table in sync. Before discussing how, let’s discuss why you might want to have a staging table at all. Why not just process changes directly in the production table?
The main reason is to protect the production table from bad changes. Perhaps a load terminated abnormally due to file corruption, or a delete zapped more rows than planned. It’s better to back off those changes and clean up in a staging table than in a production table. Once you’re satisfied that the changes are ready to promote to production (satisfied by automatic check or manual action), you can use the change data captured in the stream to synchronize the changes to the production table.
Of course, that’s only one reason to use a CDC stream. Since it’s the most straightforward, let’s start with that one. Snowflake streams provide a powerful way to deal with changing data sets. I’ll discuss some very intriguing uses for streams in future posts.
Simplifying how to use streams
The documentation for streams is comprehensive. It covers a great deal of ground, attempting to show every capability and option. In contrast, this article presents a single simplified use case. Specifically, the common use case of pushing all changes to a staging table, and using a CDC stream to control changes to a corresponding production table. Hopefully this will allow the reader to learn from a simple example, tinker with it, and come up with your own uses.
The SQL script walks through the key concepts of Snowflake streams. A subsequent post will elaborate on some key aspects of how and why streams work the way they do. The final two SQL statements merit some discussion. The next to last one shows that a single merge statement can perform 100% of the insert, delete, and update operations in the stream in a single step. Rather than expecting you to reverse-engineer why that is, there’s an annotated SQL explaining how it works. The very last SQL statement is a handy (and in Snowflake very rapid) way to dump any differences between any number of columns in two tables.
-- Set the context. Be sure to use a test database and extra small
-- test warehouse.
use warehouse TEST;
use database TEST;
use role SYSADMIN;
-- Create a schema to test streams
create or replace schema TEST_STREAMS;
-- Create a STAGING table to hold our changed data for our CDC pipeline
create or replace table STAGING
(ID int, CHANGE_NUMBER string, HOW_CHANGED string, FINAL_VALUE string);
-- Create the target PRODUCTION table with a schema identical to STAGING
create or replace table PRODUCTION like STAGING;
-- Create a stream on the STAGING table
create or replace stream STAGING_STREAM on table STAGING;
-- Examine the STAGING table... It's a simple, four-column table:
select * from STAGING;
-- Examine the STAGING_STREAM... It's got 3 new columns called
-- METADATA$ACTION, METADATA$ISUPDATE, and METADATA$ROW_ID
select * from STAGING_STREAM;
-- 1st change to STAGING table
-- Let's insert three rows into the STAGING table:
insert into STAGING (ID, CHANGE_NUMBER, HOW_CHANGED, FINAL_VALUE) values
(1, '1st change to STAGING table', 'Inserted', 'Original Row 1 Value'),
(2, '1st change to STAGING table', 'Inserted', 'Original Row 2 Value'),
(3, '1st change to STAGING table', 'Inserted', 'Original Row 3 Value');
-- Let's look at the STAGING table now to see our three rows:
select * from STAGING;
-- Now, let's look at our stream. Notice there are three "INSERT" metadata
-- actions and three FALSE for metadata "ISUPDATE":
select * from STAGING_STREAM;
-- The documentation for streams discusses how DML operations will advance the
-- position of the stream. Note that a SELECT is *not* a DML operation, and will
-- not advance the stream. Let's run the select again and see all three rows are
-- still there no matter how many times we SELECT from the stream:
select * from STAGING_STREAM;
-- Recall that a Snowflake stream indicates all the changes you need to make
-- to keep a target table (PRODUCTION) in sync with the staging table where the
-- stream is tracking the changes (STAGING). With this preamble, can you guess
-- what will happen when you delete all rows in the staging table *before*
-- you consume the stream?
-- 2st change to STAGING table
delete from STAGING;
-- Let's SELECT from STAGING_STREAM and see what's there:
select * from STAGING_STREAM;
-- There are no rows. Why is this? Why does the stream not show the three
-- inserted rows and then the three deleted rows? Recall the underlying purpose
-- of Snowflake streams, to keep a staging and production table in sync. Since
-- we inserted and deleted the rows *before* we used (consumed) the stream in
-- a DML action, we didn't need to insert and delete the rows to sync the tables.
-- Now, let's reinsert the rows:
-- 3rd change to STAGING table
insert into STAGING (ID, CHANGE_NUMBER, HOW_CHANGED, FINAL_VALUE) values
(1, '3rd change to STAGING table', 'Inserted after deleted', 'Original Row 1 Value'),
(2, '3rd change to STAGING table', 'Inserted after deleted', 'Original Row 2 Value'),
(3, '3rd change to STAGING table', 'Inserted after deleted', 'Original Row 3 Value');
-- Now let's look at the stream again. We expect to see three inserts of the
-- new change:
select * from STAGING_STREAM;
-- Okay, now let's show what happens when you use the stream as part of a DML
-- transaction, which is an INDERT, DELETE, UPDATE, or MERGE:
insert into PRODUCTION
select ID, CHANGE_NUMBER, HOW_CHANGED, FINAL_VALUE from STAGING_STREAM;
-- The rows are in PRODUCTION:
select * from PRODUCTION;
-- But since you've "consumed" the stream (advanced its position by using rows
-- in a DML transaction), this will show no rows:
select * from STAGING_STREAM;
-- Why is this? It's helpful to think of the existence of rows in a stream (strictly
-- speaking, rows past the last consumed position of the stream) as an indication
-- that there have been unprocessed changes in your change data capture stream.
-- To see how this works, let's make some more changes:
-- Update a row to see how the stream responds:
update STAGING
set FINAL_VALUE = 'Updated Row 1 Value',
HOW_CHANGED = 'Updated in change 4'
where ID = 1;
-- Examine the change in the staging table:
select * from STAGING;
-- Since the last time you consumed the stream, you have one UPDATE to process.
-- Let's see what that looks like in the stream:
select * from STAGING_STREAM;
-- There are *two* rows. Why is that? The reason is how Snowflake processes updates.
-- In order to enable Snowflake Time Travel and for technical reasons, Snowflake
-- processes an UPDATE as a DELETE and an INSERT. Note that we can tell this is
-- an update, because there's another column, "METADATA$ISUPDATE" set to TRUE.
-- Let's process this change. We'll start with the DELETE first:
delete from PRODUCTION
where ID in (select ID from STAGING_STREAM where METADATA$ACTION = 'DELETE');
-- We've now deleted row ID 1, let's check it and then do the INSERT:
select * from PRODUCTION;
-- But wait... What happened to the stream? Did it clear out only the DELETE
-- metadata action because that's the only one you used in the DML?
select * from STAGING_STREAM;
-- Answer: ** No **. Even though you didn't use every row in the stream, *any*
-- DML transaction advances the stream to the end of the last change capture.
-- You could use "begin" and "end" to do the INSERT and DELETE one after the
-- other, or we could use UPDATE by checking the "METADATA$ISUPDATE", but I'd
-- like to propose a better, general-purpose solution: MERGING from the stream.
-- Let's see how this works. First, let's get the PRODUCTION table back in sync
-- with the STAGING table:
delete from PRODUCTION;
insert into PRODUCTION select * from STAGING;
-- Now, let's do an INSERT, UPDATE, and DELETE before "consuming" the stream
select * from STAGING;
insert into STAGING (ID, CHANGE_NUMBER, HOW_CHANGED, FINAL_VALUE)
values (4, '5th change to STAGING table', 'Inserted in change 5', 'Original Row 5 value');
update STAGING
set CHANGE_NUMBER = '6th change to STAGING table', HOW_CHANGED = 'Updated in change 6'
where ID = 2;
delete from STAGING where ID = 3;
-- Now your STAGING and PRODUCTION tables are out of sync. The stream captures
-- all changes (change data capture or CDC) needed to process to get the tables
-- in sync:
select * from STAGING_STREAM;
-- Note that we have *FOUR* rows after making one change for each verb
-- INSERT, UPDATE, and DELETE. Recall that Snowflake processes an UPDATE as
-- a DELETE followed by an INSERT, and shows this in the METADATA$ISUPDATE
-- metadata column.
-- What if all you want to do is keep PROD in sync with STAGING, but control
-- when those changes happen and have the option to examine them before
-- applying them? This next DML statement serves as a template to make this
-- use case super easy and efficient:
-- Let's look at the PRODUCTION table first:
select * from PRODUCTION;
-- Merge the changes from the stream. The graphic below this SQL explains
-- how this processes all changes in one DML transaction.
merge into PRODUCTION P using
(select * from STAGING_STREAM where METADATA$ACTION <> 'DELETE' or METADATA$ISUPDATE = false) S on P.ID = S.ID
when matched AND S.METADATA$ISUPDATE = false and S.METADATA$ACTION = 'DELETE' then
delete
when matched AND S.METADATA$ISUPDATE = true then
update set P.ID = S.ID,
P.CHANGE_NUMBER = S.CHANGE_NUMBER,
P.HOW_CHANGED = S.HOW_CHANGED,
P.FINAL_VALUE = S.FINAL_VALUE
when not matched then
insert (ID, CHANGE_NUMBER, HOW_CHANGED, FINAL_VALUE)
values (S.ID, S.CHANGE_NUMBER, S.HOW_CHANGED, S.FINAL_VALUE);
-- Recall that you did 1 INSERT, 1 UPDATE, and 1 DELETE. The stream captured
-- all three changes, and the MERGE statement above performed all three in one
-- step. Now the PRODUCTION table is in sync with STAGING:
select * from PRODUCTION;
-- We consumed the stream, so it's advanced past any changes to show there's
-- nothing remaining to process:
select * from STAGING_STREAM;
-- We can process CDC streams any way we want, but to synchronize a staging
-- and production table, this MERGE template works great.
-- BTW, here's a handy trick to see if two tables that are supposed to be in
-- sync actually are in sync. There's a complete post on it here:
-- https://snowflake.pavlik.us/index.php/2020/01/08/field-comparisons-using-snowflake/
-- This query will find any mismatched rows:
select P.ID as P_ID,
P.CHANGE_NUMBER as P_CHANGE_NUMBER,
P.HOW_CHANGED as P_HOW_CHANGED,
P.FINAL_VALUE as P_FINAL_VALUE,
S.ID as S_ID,
S.CHANGE_NUMBER as S_CHANGE_NUMBER,
S.HOW_CHANGED as S_HOW_CHANGED,
S.FINAL_VALUE as S_FINAL_VALUE
from PRODUCTION P
full outer join STAGING S
on P.ID = S.ID and
P.CHANGE_NUMBER = S.CHANGE_NUMBER and
P.HOW_CHANGED = S.HOW_CHANGED and
P.FINAL_VALUE = S.FINAL_VALUE
where P.ID is null or
S.ID is null or
P.CHANGE_NUMBER is null or
S.CHANGE_NUMBER is null or
P.HOW_CHANGED is null or
S.HOW_CHANGED is null or
P.FINAL_VALUE is null or
S.FINAL_VALUE is null;
Think of the final MERGE statement as a general-purpose way to merge changes from any staging table’s stream to its corresponding production table. In order to do that; however, you’ll need to modify the template a bit. The following graphic should help explain what’s going on here:
Administrators usually disable parent-child relational constraint enforcement, especially in OLAP databases. Snowflake allows definition of parent-child relationships, but currently does not enable enforcement. This approach enables documentation at the table and view level. It also allows integration with Entity Relationship Diagram (ERD) solutions or custom data dictionaries.
Snowflake stores the relationship information in the table Data Definition Language (DDL) representation of each table or view. Since there appears to be no centralized location to read the relationships, I wrote a Java project to capture them automatically.
In its present state it has some limitations. Chief among them is that I have tested it using only single-column primary and foreign keys. I think, though I have not yet confirmed, that it should work with multi-column keys. It could run into parsing issues due to differences in how Snowflake stores DDL lines for multi-column primary and foreign keys. This should be a simple problem to address, but I’ve not yet tested it.
The attached Java project, Snowflake_Utilities, has a class named SchemaInfo. The SchemaInfo class will collect more schema information in future updates. The initial preview focuses on collecting relationship information. It can:
Return a primary key for a table or view
Return all foreign keys defined for a table or view, along with the name and key on the parent
Get all primary keys for every table and view across an entire Snowflake account
Get all foreign keys for every table and view across an entire Snowflake account
The included Java source, exported from Eclipse, should be easy to configure. The main thing to add to the project build path is the latest Snowflake JDBC driver.
There are a lot of reasons why it may be necessary to compare the values of some but not all fields in two tables. In billing reconciliation, one table may contain raw line items, and another table may contain lines in billing statements. Another common reason would be to verify that fields are accurate after undergoing transformation from the source system to a table optimized for analytics.
Obviously when moving and transforming data a lot can happen along the way. Probably the most common problem is missing rows, but there are any number of other problems: updates out of sync, data corruption, transformation logic errors, etc.
How to compare fields across tables in Snowflake
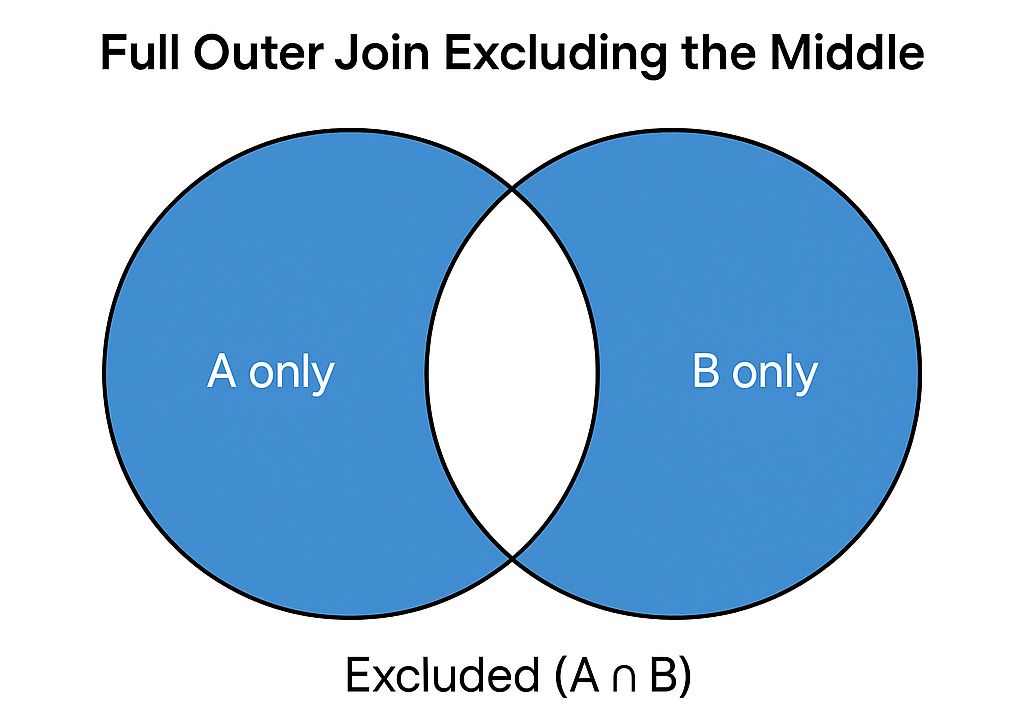
Fortunately, Snowflake’s super-fast table joining provides a great way to check for missing rows or differences in key fields between the tables. Without getting into Venn diagrams with inner, outer, left, right, etc., suffice it to say we’re going to discuss what is perhaps the least used join: the full outer exclusive of inner join. I’ve seen this type of join called other names, but this is what it does:
Think of it this way for the present use case: The excluded inner join excludes the rows with key fields that compare properly. In other words, if our reconciliation process on key fields between tables A and B is perfect, an inner join will return all rows. Turning that on its head, the inverse of an inner join (a full join exclusive of inner join) will return only the rows that have key field compare mismatches.
Snowflake performance for massive-scale field comparisons
The TPCH Orders tables used as a source has 150 million rows in it. Using this approach to compare four field values on 150 million rows, the equivalent of doing 600 million comparisons completed in ~12 seconds on an extra large cluster. This level of performance exceeds by orders of magnitude typical approaches such as using an ETL platform to perform comparisons and write a table of mismatched rows.
We can see how this works in the following Snowflake worksheet:
-- Set the context
use warehouse TEST;
use database TEST;
create or replace schema FIELD_COMPARE;
use schema FIELD_COMPARE;
-- Note: This test goes more quickly and consumes the same number of credits by temporarily
-- scaling the TEST warehouse to extra large. The test takes only a few minutes.
-- Remember to set the warehouse to extra small when done with the table copies and query.
-- The test will work on an extra small warehouse, but it will run slower and consume the
-- same number of credits as running on an extra large and finishing quicker.
alter warehouse TEST set warehouse_size = 'XLARGE';
-- Get some test data, in this case 150 million rows from TPCH Orders
create table A as select * from SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.ORDERS;
create table B as select * from SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.ORDERS;
-- Quick check to see if the copy looks right.
select * from A limit 10;
select * from B limit 10;
-- We will now check to be sure the O_ORDERKEY, O_CUSTKEY, O_TOTALPRICE, and O_ORDERDATE fields
-- compare properly between the two tables. The query result will be any comparison problems.
-- Because we have copied table A and B from the same source, they should be identical. We expect
-- That the result set will have zero rows.
select A.O_ORDERKEY as A_ORDERKEY,
A.O_CUSTKEY as A_CUSTKEY,
A.O_ORDERSTATUS as A_ORDERSTATUS,
A.O_TOTALPRICE as A_TOTALPRICE,
A.O_ORDERDATE as A_ORDERDATE,
A.O_ORDERPRIORITY as A_ORDERPRIORITY,
A.O_CLERK as A_CLERK,
A.O_SHIPPRIORITY as A_SHIPPRIORITY,
A.O_COMMENT as A_COMMENT,
B.O_ORDERKEY as B_ORDERKEY,
B.O_CUSTKEY as B_CUSTKEY,
B.O_ORDERSTATUS as B_ORDERSTATUS,
B.O_TOTALPRICE as B_TOTALPRICE,
B.O_ORDERDATE as B_ORDERDATE,
B.O_ORDERPRIORITY as B_ORDERPRIORITY,
B.O_CLERK as B_CLERK,
B.O_SHIPPRIORITY as B_SHIPPRIORITY,
B.O_COMMENT as B_COMMENT
from A
full outer join B
on A.O_ORDERKEY = B.O_ORDERKEY and
A.O_CUSTKEY = B.O_CUSTKEY and
A.O_TOTALPRICE = B.O_TOTALPRICE and
A.O_ORDERDATE = B.O_ORDERDATE
where A.O_ORDERKEY is null or
B.O_ORDERKEY is null or
A.O_CUSTKEY is null or
B.O_CUSTKEY is null or
A.O_TOTALPRICE is null or
B.O_TOTALPRICE is null or
A.O_ORDERDATE is null or
B.O_ORDERDATE is null;
-- Now we want to start changing some data to show comparison problems and the results. Here are some ways to do it.
-- Get two random clerks
select * from B tablesample(2);
-- Count the rows for these clerks - it should be about 3000 rows
select count(*) from B where O_CLERK = 'Clerk#000065876' or O_CLERK = 'Clerk#000048376';
-- Now we can force some comparison problems. Perform one or more of the following:
-- NOTE: *** Do one or more of the following three changes or choose your own to force comparison problems. ***
-- Force comparison problem 1: Change about 3000 rows to set the order price to zero.
update B set O_TOTALPRICE = 0 where where O_CLERK = 'Clerk#000065876' or O_CLERK = 'Clerk#000048376';
-- Force comparison problem 2: Delete about 3000 rows.
delete from B where O_CLERK = 'Clerk#000065876' or O_CLERK = 'Clerk#000048376';
-- Force comparison problem 3: Insert a new row in only one table.
insert into B (O_ORDERKEY, O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE) values (12345678, 12345678, 'O', 99.99, '1999-12-31');
-- Now run the same join above to see the results. You if you make any changes to the joined fields, you should see rows.
-- INSERT of a row to table B will show up as ONE row, A side all NULL and B side with values.
-- UPDATE of a row to table B will show up as TWO rows, one row A side with values and B side with all NULL, and one row the other way
-- DELETE of a row in table B will show up as ONE row, values in the A side and B side all NULL
-- Clean up:
drop table A;
drop table B;
drop schema FIELD_COMPARE;
alter warehouse TEST set warehouse_size = 'XSMALL';
alter warehouse TEST suspend;