Programming Note
This is a continuation of the Part 1 and Part 2 of this series. Since considerable time has passed and changes made to the testing since posting those articles, this post will start from the beginning.
The Business Case for Geolocating IP Numbers
Business intelligence and data science teams can get valuable insights knowing the geolocation of website visitors. Suppose a product launch gets lots of web traffic, but the only source of information on visitors is the web log. Some web server statistics report on traffic grouped by nation, but what if we want to get much more granular information and incorporate this information with the main data warehouse?
The First Step – Getting Web Visitor IP Numbers
Let???s take one sample web server among many, Apache Web Server, and quickly examine the structure of a log entry. Here???s a line in a sample Apache Web Server log.
64.242.88.10 - - [07/Mar/2004:16:05:49 -0800] "GET /twiki/bin/edit/Main/Double_bounce_sender?topicparent=Main.ConfigurationVariables HTTP/1.1" 401 12846
In the Apache documentation, we can get more detailed information on the meaning of each field in the line, but for now we???re going to concentrate on 1) how to load the web logs into Snowflake, and 2) the key aspects for business intelligence and geolocation.
Importing Web Log Data
Loading the data is a quick proposition. Even without reading the Apache documentation it???s clear that the web log is space delimited and wraps any fields with spaces inside double quotes. Snowflake provides a very simple way to ingest structured data in flat files using File Formats. You can create a file format using SnowSQL (documented here: https://docs.snowflake.net/manuals/sql-reference/sql/create-file-format.html) or you can use the Snowflake Web UI (documented here: https://docs.snowflake.net/manuals/user-guide/data-load-web-ui.html#step-1-open-the-load-data-wizard).
Note: Although the Apache Web Log is space delimited, we will use the CSV option for the Snowflake File Format ??? simply change the delimiter from a comma to a space.
Note: For this exercise, we’ll use a database named WEBLOG. The Apache Web Server data will go into a schema named APACHE_WEB_SERVER, and the geolocating data will go in a schema named IP2LOCATION. You can change the sample code as necessary if you’d prefer to use another database or different schema names.
Here is the Snowflake File Format you can use to import Apache Web Server logs:
ALTER FILE FORMAT "WEBLOG"."APACHE_WEB_SERVER".APACHE_WEB_LOG SET COMPRESSION = 'AUTO'
FIELD_DELIMITER = ',' RECORD_DELIMITER = '\n' SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY = '\042' TRIM_SPACE = FALSE ERROR_ON_COLUMN_COUNT_MISMATCH = FALSE
ESCAPE = 'NONE' ESCAPE_UNENCLOSED_FIELD = '\134' DATE_FORMAT = 'AUTO'
TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('');
Where to Get Sample Apache Web Server Logs
One of the thing needed to test geolocating a web server log is, well, a web server log. As it turns out, this is not an easy thing to do. After some research, I located a partially obfuscated Apache web log from the US Securities and Exchange Commission (SEC) available here:
https://www.sec.gov/dera/data/edgar-log-file-data-set.html
Their weblogs obfuscate the final quad of the IPv4 dotted quad, so they look like this: 192.168.1.jjr.
After loading the data, we now need to geolocate the web hits. Problem: the Apache Web Server log, as most web logs, does not show anything for geolocation. Fortunately in most cases, we can use the visitor???s IP address to get fairly accurate geolocation.
Later in this article, we’ll show how to convert the partially obfuscated IP dotted quad for use in geolocation.
Where to Get IP Number Geolocation Databases
Third party services keep up to date databases of IPv4 and IPv6 geolocation data. Once such service I found at??https://lite.ip2location.com??includes free databases with less rich information than the paid versions. In my testing I found the free databases accurate and useful, though production BI or data science work should consider the paid versions.
Another source available through Snowflake’s Data Marketplace is ipinfo.io. I have not tested their IP geolocation data source, but the schema is similar to the one provided by IP2Location and the two should work similar in this article. One advantage of using Snowflake’s Data Marketplace is that the partner keeps the data up to date using Snowflake data sharing.
If you use the IP2Location free database, here is a Snowflake File Format to import the data:
ALTER FILE FORMAT "WEBLOG"."IP2LOCATION".IP2LOCATION SET COMPRESSION = 'AUTO'
FIELD_DELIMITER = ',' RECORD_DELIMITER = '\n' SKIP_HEADER = 0
FIELD_OPTIONALLY_ENCLOSED_BY = '\042' TRIM_SPACE = TRUE ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE
ESCAPE = 'NONE' ESCAPE_UNENCLOSED_FIELD = '\134' DATE_FORMAT = 'AUTO'
TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('\\N');
After copying the file to a stage named IP2LOCATION, You can then copy the data into a table using this COPY INTO statement:
create table IP_TO_LOCATION as
select $1::int as START_IP,
$2::int as END_IP,
$3::string as ISO_COUNTRY,
$4::string as COUNTRY,
$5::string as STATE_PROVINCE,
$6::string as CITY,
$7::double as LATITUDE,
$8::double as LONGITUDE,
$9::string as POSTAL_CODE,
$10::string as TZ_OFFSET
from @IP2LOCATION (file_format => 'IP2LOCATION');
Preparing the Data
The next question is how to resolve millions or billions of web log lines??? IP address to approximate geolocation. This is where Snowflake shines. The IP2Location LITE comes as a flat structured file with millions of rows After creating another Snowflake File Format, it???s an easy matter to turn the IP2Location flat file into a Snowflake table. From there, Snowflake???s powerful massive-scale join make it a simple matter to create a joined view that shows the IP???s approximate location.
Before using the geolocation data, there’s a data preparation item to get it working. The IP2Location data comes with IPs represented by 32-bit integers, not the familiar dotted quad notation. This makes it much easier to use code and database routines that search for ranges of IPs that all happen to be in the same area by specifying a lower and upper range for the IP number.
IP Dotted Quad: IP 32-bit Integer, Decimal
192.168.1.1 3232235777
This means we need to convert our dotted quad values into 32-bit integer values. Fortunately, Snowflake makes that easy with a UDF (User Defined Function):
--Convert an IPv4 Dotted Quad into an IP Number
create or replace function IpToInteger(ipAddress varchar)
returns double
language javascript
strict
as '
var ipQuad = IPADDRESS.split(".");
var quad1 = parseInt(ipQuad[0]);
var quad2 = parseInt(ipQuad[1]);
var quad3 = parseInt(ipQuad[2]);
var quad4 = parseInt(ipQuad[3]);
return (quad1 * 16777216) + (quad2 * 65536) + (quad3 * 256) + quad4;
';
Simulating the Partially Obfuscated IP Number:
If you don’t have your own web logs and are using the ones mentioned in this article from the SEC, they obfuscate the final quad of the IPv4 dotted quad, so they look like this: 192.168.1.jjr.
According to the SEC’s documentation, their method will always replace the final number from 0 to 255 with the same three-letter value. The SEC does not disclose that ???jjr??? maps to something like 134, but for the purposes of this test it???s acceptable to assign all 256 unique three letter replacements with numbers from 0 to 255.
After downloading the log file named ???log20170630.zip???, we need to load it to a stage and use a file format to parse it. Here is the file format I used:
ALTER FILE FORMAT "TEST"."IP2LOCATION".IP_LOG SET COMPRESSION = 'AUTO' FIELD_DELIMITER = ','
RECORD_DELIMITER = '\n' SKIP_HEADER = 1 FIELD_OPTIONALLY_ENCLOSED_BY = 'NONE' TRIM_SPACE = TRUE
ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE ESCAPE = 'NONE' ESCAPE_UNENCLOSED_FIELD = '\134'
DATE_FORMAT = 'AUTO' TIMESTAMP_FORMAT = 'AUTO' NULL_IF = ('\N');
After loading the data into a table (I called mine IP_TO_LOCATION in the WEBLOG database and IP2LOCATION schema), the next thing to do is replace the three-letter obfuscated replacements with numbers from 0 through 255. To do this, I ran an ELT process replace these values using these steps:
Step 1: Create a new table with all the columns from the original web log, plus a new column to hold the last three characters of the IP number (the three-letter replacement).
Step 2: Create a table with each of the distinct values in the new column. There will be 256 representing numbers from 0 through 255. For the purposes of this exercise, it is not important which numbers map to which three-letter replacements, so I assigned them in sequential order from 0 through 255 in the order returned in the select distinct query. I called these IP numbers simulated, even though only the final quad of the dotted quads is simulated.
Step 3: Convert the IP dotted quads into IP numbers using the UDF in Part 1 of this series. The SQL looks like this:
create table WEB_LOG_ENRICHED as
(
select IpToInteger(SIMULATED_IP) as IP_NUMBER,
IP, SIMULATED_QUAD, SIMULATED_IP, REQUEST_DATE, REQUEST_TIME, ZONE, CIK, ACCESSION,
EXTENSION, CODE, SIZE, IDX, NOREFER, NOAGENT, FIND, CRAWLER, BROWSER
from IP_LOG) -- Note: IP_LOG holds the raw Apache Web Server logs
Simulating the IP Numbers at Scale
I was concerned about performance running a Javascript UDF millions of 20,488,579 times to convert IP dotted quads into IP numbers. It turned out I needn???t have been concerned. Snowflake converted all 20.5 million in 16.97 seconds using an Extra Small (XS) warehouse. Out of curiosity, I dropped the resulting table and increased the size of the warehouse to a medium (M) and it ran in 7.85 seconds. This provides empirical evidence that increasing the warehouse size improves performance including those with UDFs.
This led me to the final part of the experiment ??? resolving the IP numbers in the web log to the geolocations. We have the IP numbers in the a log table, and the IP geolocations in another. My first thought was to join the tables, but this is an unusual join. The standard join matches keys. In this example, we need to use inequalities to join the table. In other words, join the IP log information with the geolocation data where the IP log???s IP number falls between the lower and upper bounds of a locations address range.
Geolocating the Web Hits
This leads to the final part of the experiment ??? resolving the IP numbers in the web log to the geolocations. We have the IP numbers in the a log table, and the IP geolocations in another. My first thought was to join the tables, but this is an unusual join. The standard join matches keys. In this example, we need to use inequalities to join the table. In other words, join the IP log information with the geolocation data where the IP log???s IP number falls between the lower and upper bounds of a locations address range.
select * from "WEBLOG"."APACHE_WEB_SERVER"."WEB_LOG_ENRICHED" W
left join "WEBLOG"."IP2LOCATION"."IP_TO_LOCATION" L
on W.IP_INT >= L.START_IP and W.IP_INT <= L.END_IP limit 100;
While this works, the performance was not practical for at scale usage. In this test, geocoding 100 web log entries on an extra small warehouse (single node) took about 30 seconds. That simply won’t scale.
Performance Tuning the Geolocation
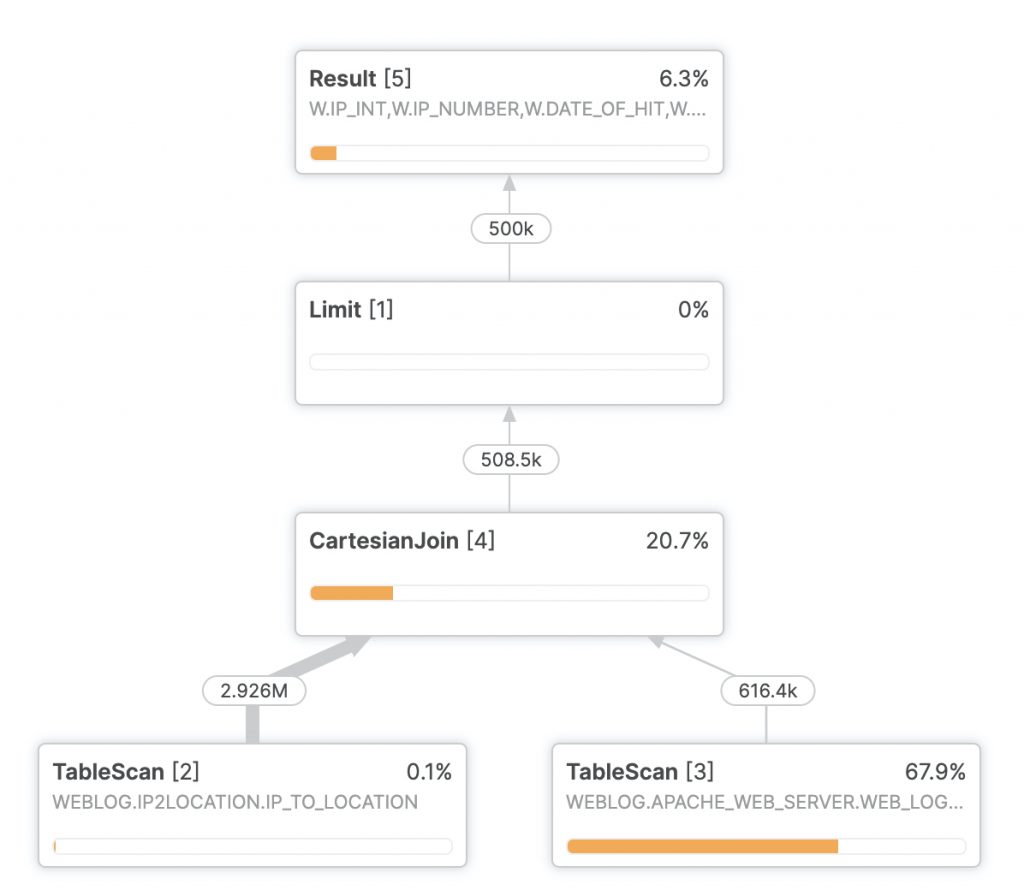
In most cases the first step in improving a Snowflake query is examining the query profiler. Here’s the query profile for the first test run of the geolocation:
The left outer join seems to be the culprit here. It turns out Snowflake’s optimizer doesn’t particularly like doing a left outer join on an inequality. The interesting thing about that is this should be a one to one relationship. For each IP number in the web log, there should be exactly one row where that IP number falls into the right range.
This allows us to do a cartesian join instead:
select * from "WEBLOG"."APACHE_WEB_SERVER"."WEB_LOG_ENRICHED" W
inner join "WEBLOG"."IP2LOCATION"."IP_TO_LOCATION" L
on W.IP_INT >= L.START_IP and W.IP_INT <= L.END_IP limit 500000;
This leads to a query profile like this:
More important, it leads to performance like this on an extra small warehouse:
After running an initial query that took a few seconds and got the critical IP geolocation table into the cache, geolocating half a million web log entries took just five seconds.